

Ijraset Journal For Research in Applied Science and Engineering Technology
Next-Gen Linguistic Intelligence Image Summarizer for Documents Using Attention Model
Authors: Dr. Karthik Elangovan, R.S Tabares Ahamed, J Somesh, Afjal Sk
DOI Link: https://doi.org/10.22214/ijraset.2024.61650
Certificate: View Certificate
Abstract
Introduction
I. INTRODUCTION
In the digital era, the exponential growth of textual data presents a significant challenge: how to effectively manage, analyse, and distill this vast amount of information. While traditional text summarization methods have been valuable, they often struggle to capture the intricate essence of complex documents and present information in visually engaging ways.
Recognizing this challenge, our project embarks on an innovative endeavor: the creation of a Next-Generation Linguistic Intelligence Image Summarizer for Documents using an Attention Model. At its core, our project seeks to redefine the landscape of textual information summarization and presentation by leveraging advanced attention mechanisms and sophisticated linguistic intelligence algorithms. Unlike conventional approaches that simply produce textual summaries, our novel method takes a significant leap forward by converting summarized text into visually intuitive representations. By doing so, our aim is to offer users a more immersive and efficient way to comprehend intricate documents. A central aspect of our project involves integrating advanced attention mechanisms, which enable our system to dynamically focus on the most relevant aspects of the input text. This ensures that the resulting visual representations not only capture the essence of the document but also do so in a coherent and meaningful manner. Furthermore, by incorporating linguistic intelligence algorithms, our system goes beyond surface-level summarization to extract semantic meaning and context from the text. This enriches the visual summaries, providing users with deeper insights into the content. Through the synergistic combination of attention mechanisms and linguistic intelligence, our project strives to bridge the gap between textual information and visual comprehension. Our ultimate goal is to empower individuals and organizations with a fresh perspective on document summarization—one that not only enhances efficiency but also fosters deeper engagement and understanding. Our project marks a step, in the realm of processing textual information by converting text into visual form. Through rethinking how information is summarized and presented our goal is to provide users with the tools they need to navigate the world of data in today's digital era all presented in an engaging visual format.
II. LITERATURE SURVEY
In recent years, much of the focus in text summarization has revolved around extractive techniques, where sentences and phrases are identified in a document and reproduced as a text summary again. Numerous research have evaluated the quality of automatic text summarization systems using datasets, attention models, and assessment approaches. [34] used neural networks to convert phrases into vectors, whereas Nallapati et al. [21] and Cheng and Lapata [3] used RNNs to generate document representations. Narayan et al. [23] used a sentence classifier to choose sentences based on titles and picture captions. Yasunaga et al. [33] used graph convolutional networks and RNNs to evaluate sentence significance. Readability problems frequently plague extractive summarization methods, even if some of them get excellent ROUGE ratings.
In contrast to neural models, abstractive document summarization has not, until recently, gotten enough attention.. Jing [15] was among the first to create summaries by eliminating unimportant parts of sentences. The task of creating summaries using methods became standardized during the DUC 2003 and 2004 competitions. TOPIARY [35] found success, in the challenge by using compression techniques and detection algorithms based on language principles. They also added keywords from a document to the result. Cheung and Penn [4] fused sentences using dependency trees, while Rush et al. [25] We present a current neural network for abstractive text summarization that uses convolutional models for text encoding and an attentional feed forward neural network for summary synthesis. Vinyals et al. [28] developed a pointer network using the soft attention distribution approach of Bahdanau et al. [2], which has since been applied to various tasks including language modelling, neural machine translation [11], and summarization [16], [21]. An extension of this work by Rush et al. [25] replaced the decoder with an RNN to improve performance. Hu et al. [13] demonstrated promising results in Chinese dataset summarization using RNNs, while Cheng and Lapata [3] employed an RNN-based encoder-decoder for extractive text summarization. Nallapati et al. [21] utilized a sequence-to-sequence model for summarization evaluation on the CNN/DailyMail dataset. Ranzato et al. [24] replaced the traditional training matrix with evaluation matrices such as ROUGE and BLEU, while See et al. [26] and Jin et al. [16] adopted pointer networks to handle out-of-vocabulary words in their models. Yadav et al. [7] used reinforcement learning with an attention layer, whereas Li et al. [17] used generative adversarial networks to get high ratings in human assessments. Bahdanau et al.[1] proposed an attention mechanism, and Yang et al. [32] introduced a hierarchical attention mechanism for document classification. In a study, by Nallapati and colleagues [21] they combined attention mechanisms at both the word and sentence levels incorporating sentence attention. Furthermore there have been advancements in feature engineering for selecting features in models with a focus on meta learning [36] [37] [38] particularly emphasizing learning and adaptation even in cases of limited data availability. In our research project we introduce a model for summarizing text that involves extracting key information before generating summaries. The words are encoded with features to retain details and are then inputted into both the extractor and summarizer components. This model combines sentence level summarization from an extraction based approach and word level summarization from a generation based method. While past studies have explored attention mechanisms, the incorporation of attention to attributes within a unified framework is innovative. By utilizing word and sentence level attention within a model that encodes words, with features we aim to enhance the comprehensiveness of text summarization.




where Wcv is a trainable parameter with the vector v's length. It suggests that the previous decisions have provided the attention mechanism for the current decision. By preventing repeated phrases from coming from the same place, this supports the attention process. The act of visiting the source document's location has been made illegal by using coverage loss. The machine translation loss is not the same as the bounded coverage loss. In machine translation, there is a translation ratio; the translation ratio determines the final convergence vector's penalty. The loss function that is being used can be adjusted, as summarization does not need continuous coverage. Penalising the overlapping attention distribution and coverage to prevent reciprocal attention is the aim of the coverage loss function.
IV. EXPERIMENTAL RESULTS
A. Dataset
We evaluated the technique using the CNN/Daily Mail dataset, which included online news stories with an average of 780.9999 tokens. These articles have multi-sentence summaries, with an average of 57 tokens (3.7499 sentences). The dataset is organized into 13,777 validation pairs, 27,777 training pairs, and 11,777 test pairings.
B. The Experiments Procedure
128-dimensional word embeddings were used to train the abstracter and the extractor. We followed See et al. [26] and Nallapati et al. [22] by using 200 and 256 hidden states for the extractor and abstracter, respectively. Nallapati et al. [21] used a vocabulary size of 50,000 words. enabling handling of out-of-vocabulary words. The coverage structure and the pointer generator gave the network a minimum of 512 and 1153 trainable parameters, respectively. We used embeddings learnt during network training, rather than pre-trained embeddings [21]. Both abstractor and extractor have a learning rate of 0.16. Using the Adagrad optimizer [8], the accumulator was set to 0.1. Early stopping was used to cease network training when overfitting occurred on the validation set. The length of the source text was restricted to word tokens for training and testing, with a maximum length of 100 tokens for reference summaries. During testing, 120 tokens were decoded for comparison. To accelerate network training, we shortened the initial encoding and decoding steps to 101 and 51 tokens, respectively. The process of progressively lengthening articles until convergence was sped up by truncating them at the start of training. Furthermore, the model underwent 48,000 iterations of training with a batch size of 4. During the training of the vector representation of words, the linguistic aspects of words were concatenated with word embedding, which did not impact the training time of the main network. The end-to-end model lowered training time by minimising encoding and decoding phases. While the abstracter tried to minimise loss functions with certain values, the extractor was taught to shorten the text. The extractor and abstracter worked together to create a two-stage network in which the pre-trained extractor used sentence-level attention.
C. Findings And Conversation
The network took six days and eighteen hours to train the extractor and abstracter on an 11GB GPU with a batch size of four. After around 118 thousand iterations, the coverage mechanism was introduced, and accuracy rose rapidly throughout the early training phases. After adding coverage with a weighted coverage loss value, training continued for about 2,000 additional iterations (4 hours), leading to improved performance during testing. The network exhibited improved performance, measured by ROUGE scores [19], compared to existing approaches. The proposed two-stage approach outperformed previous work significantly, with the addition of a coverage function reducing redundancy in generated summaries.
TABLE 1 Compares the Nallapati et al. [21] model, the pointer generator [26], and the two-stage network. F-measures for unigrams (ROUGE-1), bigrams (ROUGE-2) and longest common subsequences (ROUGE-L) are shown. Scores were calculated using the
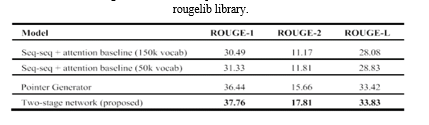
The table shows how much better the suggested two-stage method with the extractor and abstracter performed than the previous effort. Subsequent tests revealed that this enormous vocabulary of 150,000 words did not seem to be helpful for increasing efficiency. Some important information was missed by the performance efficient model. Extensive descriptions were deemed unnecessary for the majority of produced summaries, and uncommon terms were commonly substituted with more common ones. Even though OOV terms were handled using a large vocabulary technique (LVT), we still discovered word duplication in the resulting summaries. However, it was found that adding the coverage function decreased the amount of repeated words. Reducing the duplication issue came at a 1.7% cost. The feature-rich extractor summary includes the following additional information: First, read without reading the original content. Signature of Saili information Head coach Anthony addresses Saili's teammates. Second Reading: Article duration: around 2.5 minutes (full understanding). Extractive Summary of Reference: 30 seconds Feature-rich extracted summary takes around 50-1 minute.Reading for the first time Reference abstractive summary: Understanding the context of an article: On average. Characteristic Abstract and detailed synopsis.


Excellent understanding of the article's background. Finally, the feature-rich model is crucial for retaining important proper nouns, numerals, and phrases in the summary. The created summary considerably reduced the time required to read the complete information.
D. Assessment of Humans
Amazon Mechanical Turk was used for the human evaluation, and 50 test samples were chosen at random for analysis. Each sample consisted of an original article, baseline, two-stage network output, and reference summaries. On a scale of 1 to 5, evaluators graded summaries for comprehensiveness, conciseness, and informativeness. In comparison to more contemporary summarising algorithms, the two-stage model performed well, especially in terms of comprehensiveness, because it could extract information based on linguistic features. This led to higher ratings.
Conclusion
In this study, we introduced a novel approach that leverages the strengths of both extractive and abstractive summarization models to produce comprehensive summaries. Our neural network effectively extracts the main ideas from the original text by integrating a variety of linguistic variables into the word embeddings, including sentence position, numbers, POS tags, NE tags, term weights, and proper nouns.Through attention mechanisms at both the sentence and word levels, our model effectively identifies and highlights the most crucial information. Our proposed two-stage model seamlessly integrates extractive and abstractive summarization within a single framework. By training and testing on the CNN/Daily Mail dataset, we demonstrated the effectiveness of our approach, achieving a ROUGE score of 37.76%. Additionally, human evaluation confirmed the high comprehensiveness and informativeness of our generated summaries. Furthermore, we explored the conversion of summarized text into image format using parsing and other techniques. This innovative approach enhances accessibility and visualization of the summarized content, providing a more engaging and intuitive way to consume information. Overall, our study contributes to advancing the field of text summarization by offering a robust and efficient method for generating high-quality summaries, while also exploring novel avenues for presenting summarized content through image conversion techniques.
References
[1] D. Bahdanau, K. Cho, and Y. Bengio, ‘‘Neural machine translation by jointly learning to align and translate,’’ 2014, arXiv:1409.0473. [2] D. Bahdanau, J. Chorowski, D. Serdyuk, P. Brakel, and Y. Bengio, ‘‘End-to-end attention-based large vocabulary speech recognition,’’ in Proc. IEEE Int. Conf. Acoust., Speech, Signal Process., Mar. 2016, pp. 4945–4949. [3] J. Cheng and M. Lapata, ‘‘Neural summarization by extracting sentences and words,’’inProc.54thAnnu.MeetingAssoc.Comput.Linguistics(Long Papers), vol. 1, 2016, pp. 484–494. [4] J. C. K. Cheung and G. Penn, ‘‘Unsupervised sentence enhancement for automatic summarization,’’ in Proc. Conf. Empirical Methods Natural Lang. Process. (EMNLP), Oct. 2014, pp. 775–786. [5] J. Chorowski, D. Bahdanau, D. Serdyuk, K. Cho, and Y. Bengio, ‘‘Attention-based models for speech recognition,’’ in Proc. 28th Int. Conf. Neural Inf. Process. Syst., vol. 1, Jun. 2015, pp. 577–585. [6] C. A. Colmenares, M. Litvak, A. Mantrach, and F. Silvestri, ‘‘HEADS: Headline generation as sequence prediction using an abstract feature-rich space,’’ in Proc. Conf. North Amer. Chapter Assoc. Comput. Linguistics, Hum. Lang. Technol., 2015, pp. 133–142. [7] A. K. Yadav, A. Singh, M. Dhiman, R. Kaundal, A. Verma, and D. Yadav, ‘‘Extractive text summarization using deep learning approach,’’ Int. J. Inf. Technol., vol. 14, no. 5, pp. 2407–2415, 2022. [8] J. Duchi, H.Elad, and Y.Singer, ‘‘Adaptive subgradient methods for online learning and stochastic optimization,’’ J. Mach. Learn. Res., vol. 12, no. 7, pp. 1–39, Jul. 2011. [9] G. Erkan and D. R. Radev, ‘‘LexRank: Graph-based lexical centrality as salience in text summarization,’’ J. Artif. Intell. Res., vol. 22, pp. 457–479, Dec. 2004. [10] K. Filippova and Y. Altun, ‘‘Overcoming the lack of parallel data in sentence compression,’’ in Proc. Conf. Empirical Methods Natural Lang. Process. (EMNLP), Oct. 2013, pp. 1–11. [11] C. Gulcehre, O. Firat, K. Xu, K. Cho, L. Barrault, H.-C. Lin, F. Bougares, H. Schwenk, and Y. Bengio, ‘‘On using monolingual corpora in neural machine translation,’’ 2015, arXiv:1503.03535. [12] W.-T. Hsu, C.-K. Lin, M.-Y. Lee, K. Min, J. Tang, and M. Sun, ‘‘A unified model for extractive and abstractive summarization using inconsistency loss,’’ in Proc. 56th Annu. Meeting Assoc. Comput. Linguistics (Long Papers), vol. 1, 2018, pp. 132–141. [13] B. Hu, Q. Chen, and F. Zhu, ‘‘LCSTS: A large scale Chinese short text summarization dataset,’’ in Proc. Conf. Empirical Methods Natural Lang. Process., 2015, pp. 1967–1972. [14] S. Jean, K. Cho, R. Memisevic, and Y. Bengio, ‘‘On using very large target vocabulary for neural machine translation,’’ in Proc. 53rd Annu. Meeting Assoc. Comput. Linguistics 7th Int. Joint Conf. Natural Lang. Process., vol. 1, 2015, pp. 1–10. [15] H. Jing, ‘‘Sentence reduction for automatic text summarization,’’ in Proc. 6th Conf. Appl. natural Lang. Process., 2000, pp. 310–315. [16] J. Jin, P. Ji, and R. Gu, ‘‘Identifying comparative customer requirements from product online reviews for competitor analysis,’’ Eng. Appl. Artif. Intell., vol. 49, pp. 61–73, Mar. 2016. [17] J. Li, W. Monroe, T. Shi, S. Jean, A. Ritter, and D. Jurafsky, ‘‘Adversarial learning for neural dialogue generation,’’ 2017, arXiv:1701.06547. [18] C.-Y. Lin, G. Cao, J. Gao, and J.-Y. Nie, ‘‘An information-theoretic approach to automatic evaluation of summaries,’’ in Proc. Main Conf. Hum. Lang. Technol. Conf. North Amer. Chapter Assoc. Comput. Linguis tics, 2006, pp. 463–470. [19] C. Y. Lin, ‘‘Looking for a few good metrics: Automatic summarization evaluation-how many samples are enough?’’ in Proc. NTCIR, Jun. 2004, pp. 1–10. [20] S. Jadooki, D. Mohamad, T. Saba, A. S. Almazyad, and A. Rehman, ‘‘Fused features mining for depth-based hand gesture recognition to clas sify blind human communication,’’ Neural Comput. Appl., vol. 28, no. 11, pp. 3285–3294, 2017. [21] R. Nallapati, B. Zhou, C. dos Santos, C. Gulcehre, and B. Xiang, ‘‘Abstractive text summarization using sequence-to-sequence RNNs and beyond,’’ in Proc. 20th SIGNLL Conf. Comput. Natural Lang. Learn., 2016, pp. 280–290. [22] R. Nallapati, F. Zhai, and B. Zhou, ‘‘SummaRuNNer: A recurrent neural network based sequence model for extractive summarization of docu ments,’’ in Proc. 31st AAAI Conf. Artif. Intell., 2017, pp. 3075–3081. [23] S. Narayan, N. Papasarantopoulos, S. B. Cohen, and M. Lapata, ‘‘Neural extractive summarization with side information,’’ 2017, arXiv:1704.04530. [24] M. A. Ranzato, S. Chopra, M. Auli, and W. Zaremba, ‘‘Sequence level training with recurrent neural networks,’’ in Proc. 4th Int. Conf. Learn. Represent. (ICLR), 2016, pp. 1–16. [25] A. M. Rush, S. Chopra, and J. Weston, ‘‘A neural attention model for abstractive sentence summarization,’’ in Proc. Conf. Empirical Methods Natural Lang. Process., 2015, pp. 1–11. [26] A.See,P.J.Liu,andC.D.Manning,‘‘Gettothepoint:Summarizationwith pointer-generator networks,’’ in Proc. 55th Annu. Meeting Assoc. Comput. Linguistics, vol. 1, 2017, pp. 1073–1083. [27] S. Venugopalan, M. Rohrbach, J. Donahue, R. Mooney, T. Darrell, and K. Saenko, ‘‘Sequence to sequence—Video to text,’’ in Proc. IEEE Int. Conf. Comput. Vis. (ICCV), Dec. 2015, pp. 4534–4542. [28] O. Vinyals, M. Fortunato, and N. Jaitly, ‘‘Pointer networks,’’ in Proc. 28th Int. Conf. Neural Inf. Process. Syst., vol. 2, 2015, pp. 2692–2700. [29] P. Willett, ‘‘The Porter stemming algorithm: Then and now,’’ Program, Electron. Library Inf. Syst., vol. 40, no. 3, pp. 219–223, 2006. [30] K.-F. Wong, M. Wu, and W. Li, ‘‘Extractive summarization using super vised and semi-supervised learning,’’ in Proc. 22nd Int. Conf. Comput. Linguistics COLING, 2008, pp. 985–992. [31] J.Amin,M.Sharif,M.Raza,T.Saba,R.Sial,andS.A.Shad,‘‘Brain Tumor detection: A long short-term memory (LSTM)-based learning model,’’ Neural Comput. Appl., vol. 32, no. 20, pp. 15965–15973, Oct. 2020. [32] Z. Yang, D. Yang, C. Dyer, X. He, A. Smola, and E. Hovy, ‘‘Hierarchical attention networks for document classification,’’ in Proc. Conf. North Amer. Chapter Assoc. Comput. Linguistics, Hum. Lang. Technol., 2016,pp.1480–1489. [33] M.Yasunaga,R.Zhang,K.Meelu,A.Pareek,K.Srinivasan,andD.Radev, ‘‘Graph-based neural multi-document summarization,’’ in Proc. 21st Conf. Comput. Natural Lang. Learn. (CoNLL), 2017, pp. 452–462. [34] X. C. Yin, W. Y. Pei, J. Zhang, and H. W. Hao, ‘‘Multi-orientation scene text detection with adaptive clustering,’’ IEEE Trans. Pattern Anal. Mach. Intell., vol. 37, no. 9, pp. 1930–1937, Sep. 2015. [35] D. Zajic, B. Dorr, and R. Schwartz, ‘‘Topiary,’’ in Proc. HLT NAACL Document Understand. Workshop, Boston, MA, USA, 2004, pp. 112–119. [36] C. M. Bishop, Neural networks for pattern recognition, Oxford university press, 1995. [37] F. Perronnin and C. Dance, \"Fisher kernels on visual vocabularies for image categorization\", CVPR, 2007. [38] J. Long, E. Shelhamer and T. Darrell, \"Fully convolutional networks for semantic segmentation\", CVPR, 2015. [39] j.Gllavata, R. Ewerth and B. Freisleben, A robust algorithm for text detection in images, pp. 611-616 [40] kumar Anubhav, \"An efficient text extraction algorithm in complex images\", Contemporary Computing (IC3), 2013
Copyright
Copyright © 2024 Dr. Karthik Elangovan, R.S Tabares Ahamed, J Somesh, Afjal Sk. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET61650
Publish Date : 2024-05-06
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online